We built FutureSim, to evaluate how agents adapt their beliefs as new information arrives in the real-world. Agents have to forecast world events, deciding themselves when to update which forecasts, as daily news gets added to the environment. This makes FutureSim long-horizon and open-ended, while being easily reproducible and grounded in real event data. In this release we benchmark frontier agents in harnesses like Codex and Claude Code over a three month simulation. We also show how FutureSim can support emerging research on test-time adaptation, epistemic humility, memory, search, inference-scaling, and multi-agent self-play. You can run FutureSim with your own dataset of chronological events!
Design
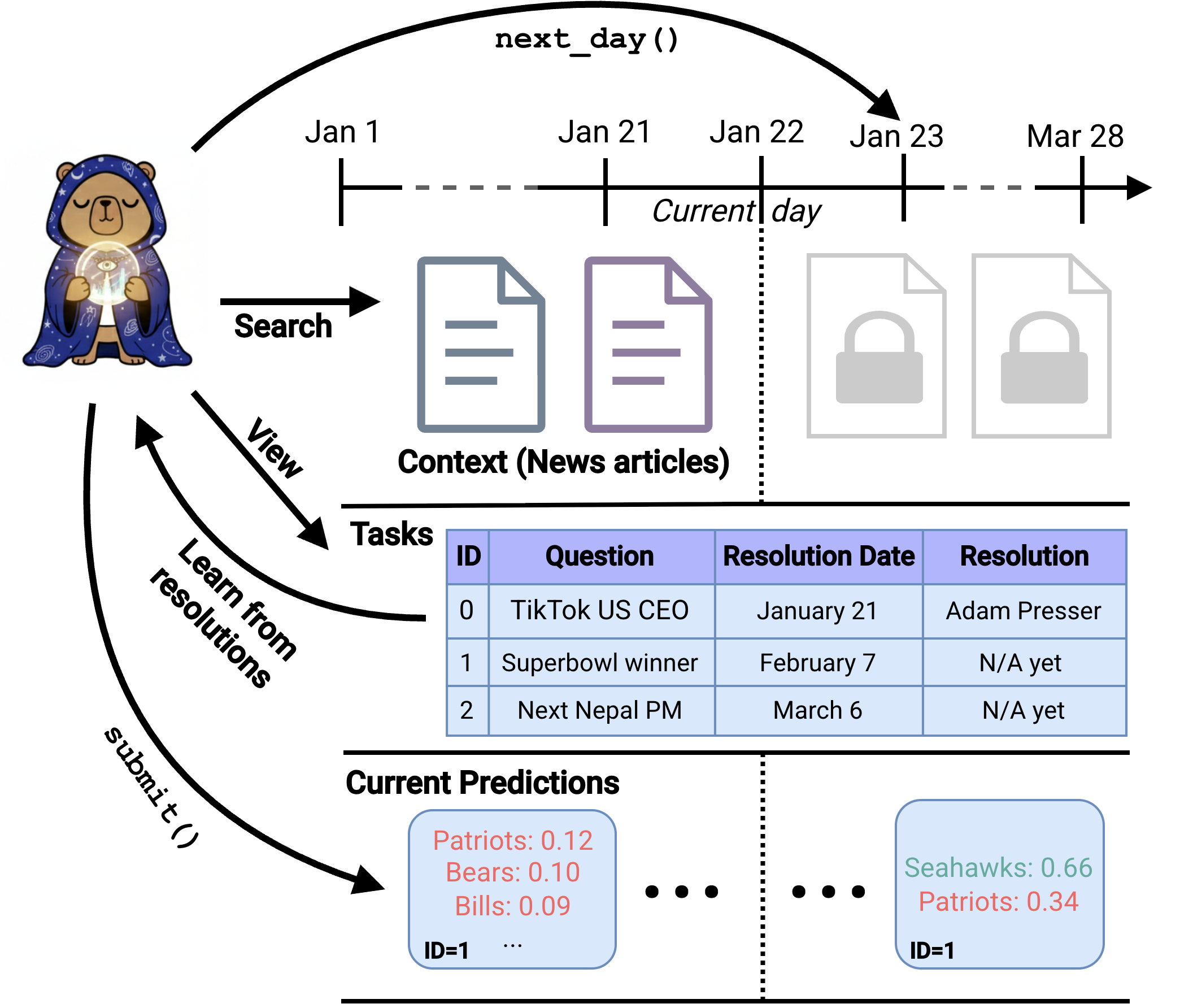
FutureSim captures several properties which we think are uniquely important for studying agent adaptation:
-
Chronological order: Our world evolves over time, and not in a random or arbitrary order. In FutureSim, the tasks and context available at each time-step correspond to a real, dated snapshot of the world.
-
Based on real-world data: Agents have to predict events that have already occurred for us, extracted from news documents. The context also updates based on CommonCrawl News, which has time-stamped snapshots that can’t be updated in the future, preventing leakage.
-
Partial observability of large context: The context consists of millions of documents. Agents have to use tools to actively seek information from the environment. We allow agent creators to define their own tools to explore this context, as long as they do not leak information beyond the current date of the simulation. In our experiments, we provide access to both terminal command based search over a time-gated article corpus, and a hybrid search tool (LanceDB) which allows controlling query date ranges.
-
Deciding when to update their attempt on which tasks: Humans choose what task merits their attention based on the context available at the time. In FutureSim, the environment maintains an overall task state, and agents can keep updating their attempts for chosen questions using the submit_forecasts() action. The only other action the environment encodes is next_day(), which agents can call once they think they’ve made sufficient use of the existing context.
-
Epistemic humility in world-modelling: Having overconfident beliefs makes one commit to wrong actions, while underconfidence leads to inaction. In FutureSim, agents must maintain calibrated predictions, by recognizing what they don’t know, while still making useful inferences and extrapolations. They must weigh relevant evidence based on learnt priors about how the world evolves.
-
Economically valuable: Reasoning about uncertain future events and acting accordingly is a central challenge when making decisions. As an anecdote, some of the questions in our dataset have prediction markets with millions of dollars in volume being traded.
Sample Agent Trajectory compared to Prediction Markets


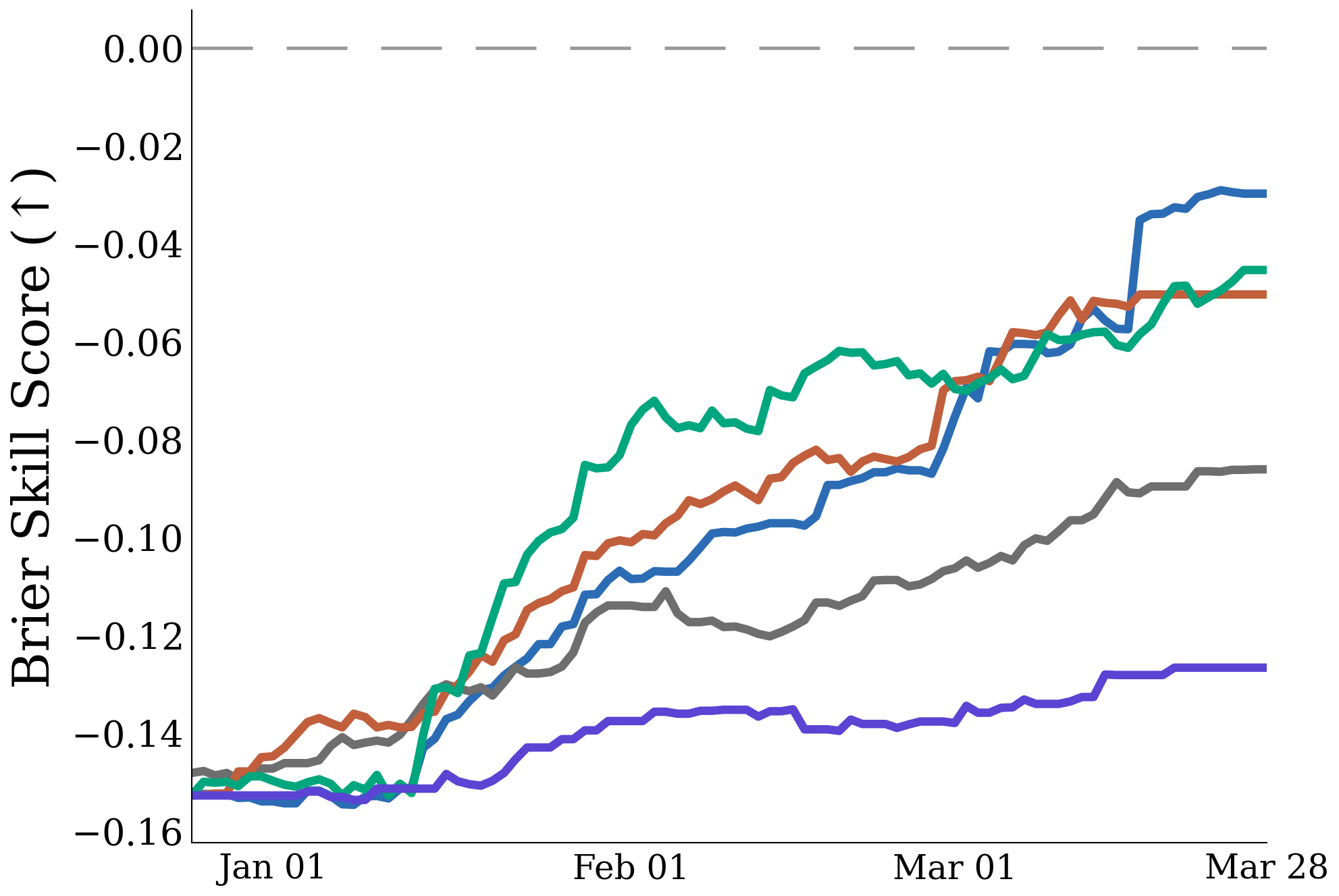
Some forecasting questions in our experiments overlap with Polymarket markets allowing comparative analysis. On several of these, GPT 5.5’s updates track the human aggregate and the cited evidence is quite reasonable. On some markets, including the Super Bowl winner market with 700M$ traded in volume, GPT 5.5 sometimes even is ahead of the crowd aggregate. On some other markets, like the Grammy and UK District Election market, it was dramatically worse than the human aggregate.
Prediction task and scoring
We use free-form forecasting questions, tasking agents to come up with multiple possible outcomes, and distribute probability over them. Here’s a sample prediction GPT 5.5 made on the Nepal elections:
submit_forecasts(
question_id="nepal_pm",
outcomes={
"Balendra Shah": 0.34,
"Khagendra Sunar": 0.18,
"Sushila Karki": 0.12,
"Kulman Ghising": 0.08,
"Gagan Thapa": 0.05,
},
)
Note that the probabilities do not need to sum to $1$; we can still use a proper scoring rule:
Brier skill score: For a resolved question with true answer $y$, let $\Omega$ be the set of outcomes submitted by the agent. For each single outcome $o \in \Omega$, $p(o)$ is the probability assigned to that outcome. If $y \notin \Omega$, we include $y$ in the sum with $p(y)=0$:
\[\mathrm{BSS}(p, y) = 1 - \sum_{o \in \Omega \cup \{y\}} \left(p(o) - \mathbf{1}[o = y]\right)^2\]Brier skill score ranges from $-1$ to $1$, and higher is better. Assigning probability $1$ to the correct answer gets scored $1$, abstaining by assigning $0$ probability gets scored $0$, and assigning probability $1$ to a wrong answer gets scored $-1$. The score is optimized when outcomes assigned $X\%$ probability are correct $X\%$ of the time.
Accuracy: As its easier to interpret, we also measure accuracy of the outcome assigned the highest probability by the agent (top-1 accuracy).
We prompt agents to maximize the sum of brier skill score over time-steps, which incentivizes correctness, calibration, as well as timeliness of predictions.
In our plots, we show the brier skill score and accuracy at each time-step based on the current predictions, but using the ground-truth answer that becomes available to the agent only later in the simulation (corresponding to the date it became known).
Task: We evaluate using 330 short-answer forecasting questions created from Al Jazeera news articles. Questions resolve between January 1 and March 28, 2026, after the knowledge cutoffs of the evaluated models, with the simulation starting on December 24, 2025 🎅🎄.
Context corpus: Agents interact with a date-gated CCNews corpus: 7.36M deduplicated articles from 141 sources. Agents can only access articles up to the current simulation date, with 244k new articles becoming available over the 88 day simulation period.
Note that the absolute performances we report can be considered a lower-bound on agent performance. Access to a larger context corpus, better tools, and harness engineering to scale inference further would elicit higher performance. At the same time, care has to be taken to avoid leakage of future information. While we would much like to give agents access to the full internet, search API’s today do not support reliable date-cutoffs.
Frontier model evaluations
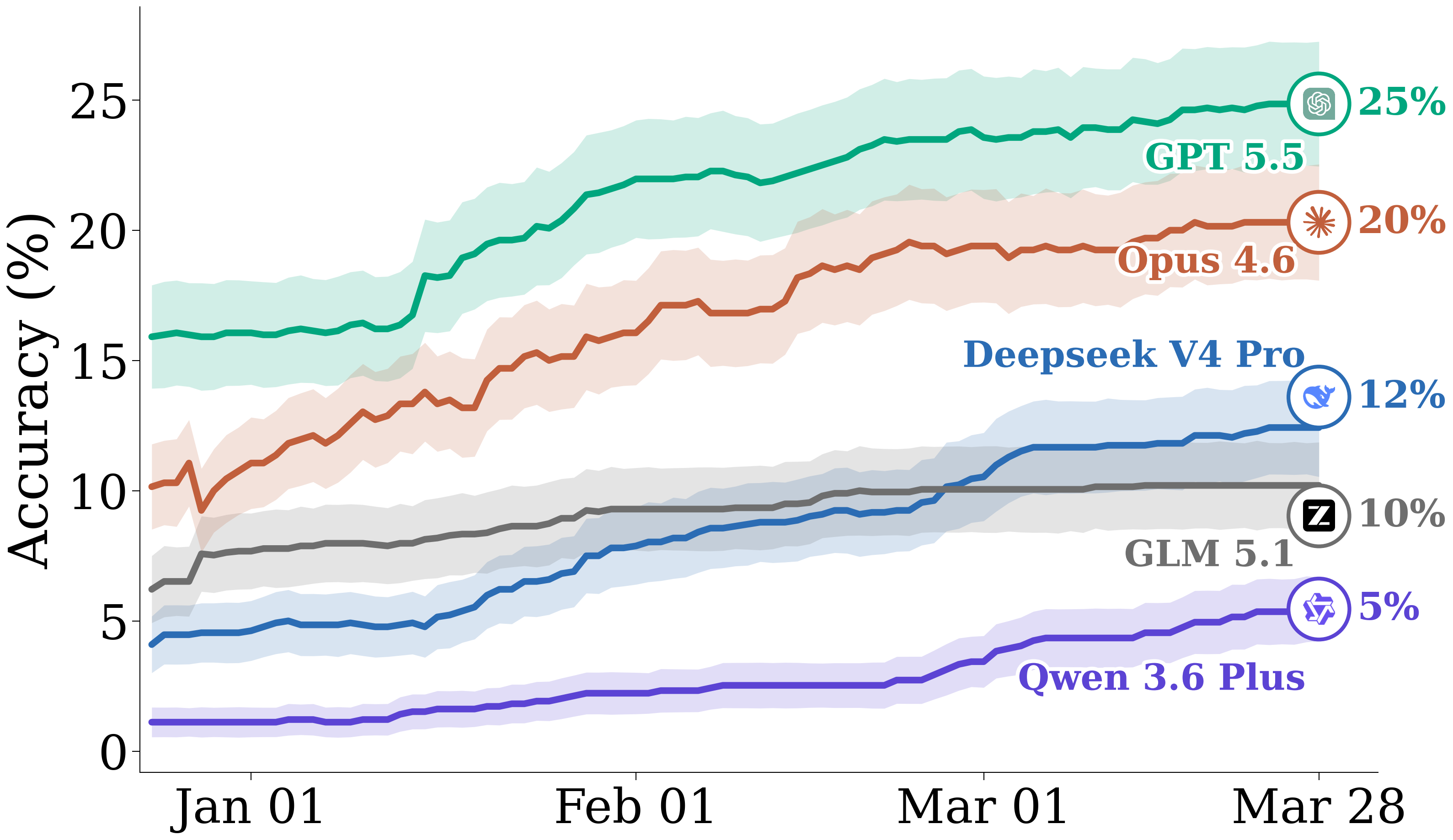
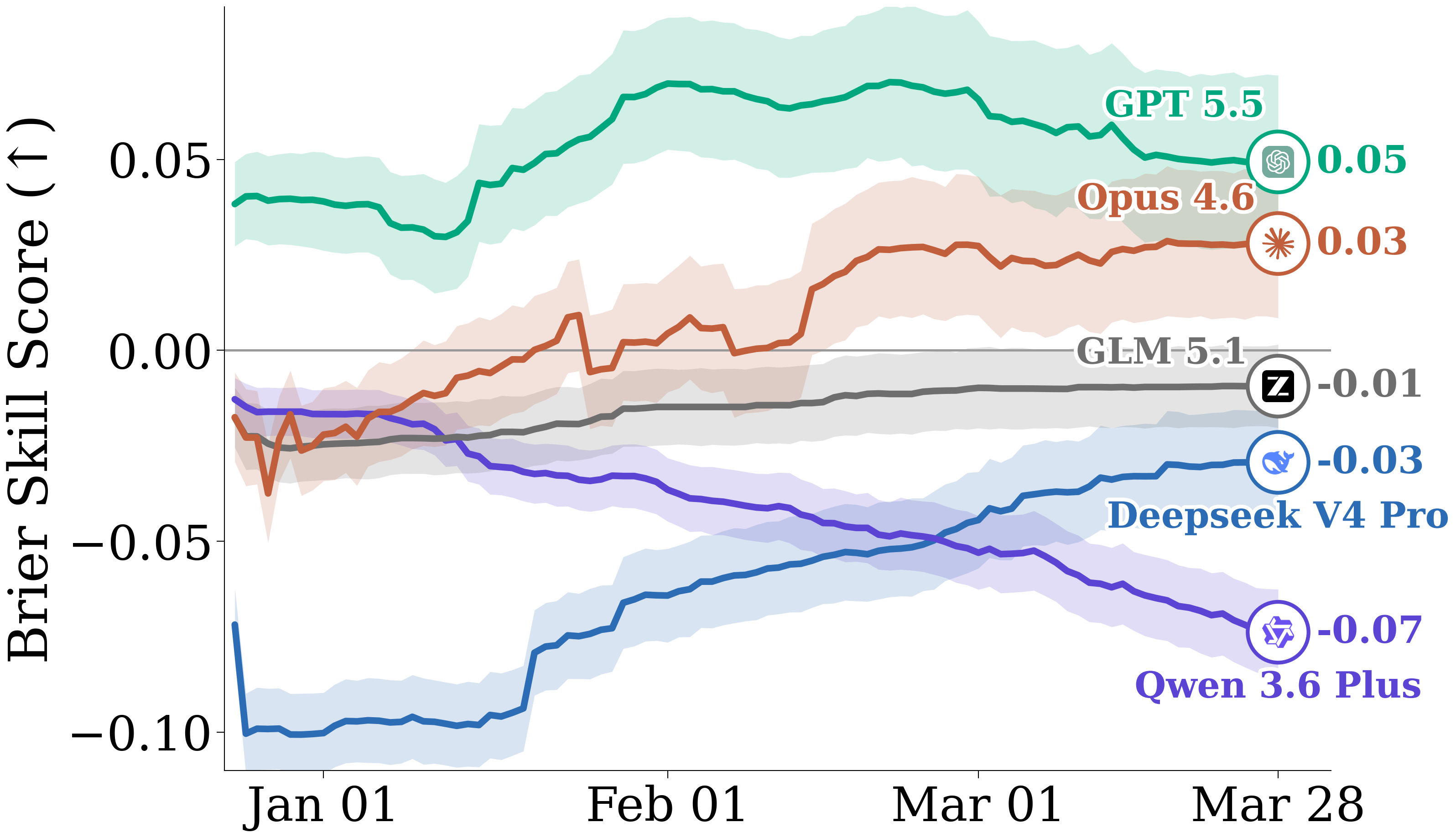
We evaluate GPT 5.5 in Codex, Qwen3.6 Plus in OpenCode, and Opus 4.6, DeepSeek V4 Pro, and GLM 5.1 in Claude Code. In our paper, we also report improved results across agents from adding a common set of modifications (such as in memory management) to all harnesses, showing gains from further harness engineering as possible.
We observe GPT 5.5 performs best on both accuracy and Brier skill score. Claude Opus 4.6 starts worse than GPT 5.5, but is also able to improve significantly from test-time adaptation.
Open-weight models lag behind, but show interesting trends. For example, while DeepSeek V4 Pro’s much better adaptation at test-time helps it close the gap on GLM 5.1, Qwen 3.6 Plus worsens in Brier skill score during the simulation, overconfidently reinforcing its existing predictions.
How researchers/developers can use FutureSim
Finally, we show how FutureSim flexible design enables experiments on various interesting research directions. Pick your favorite ones below :)

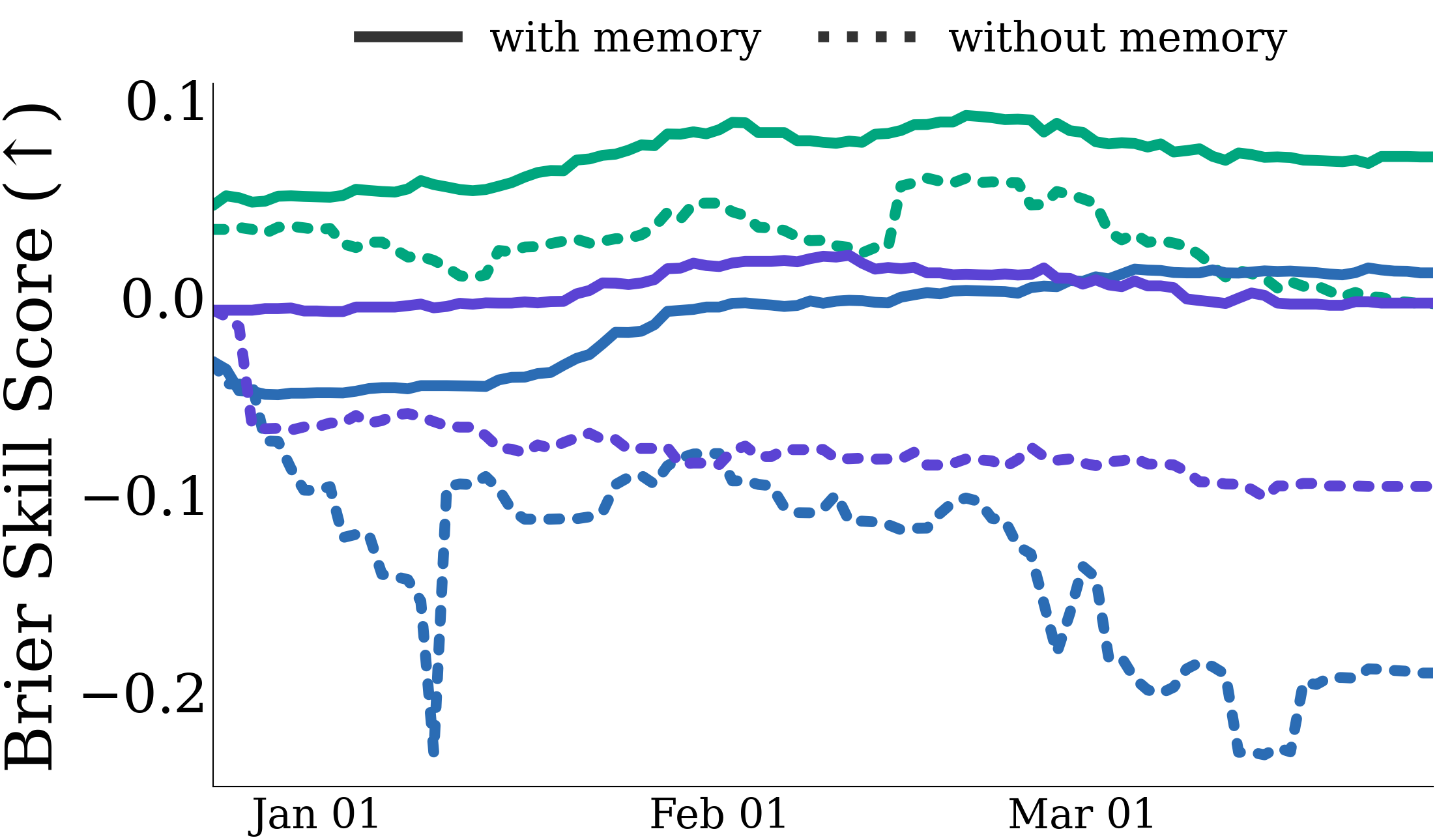
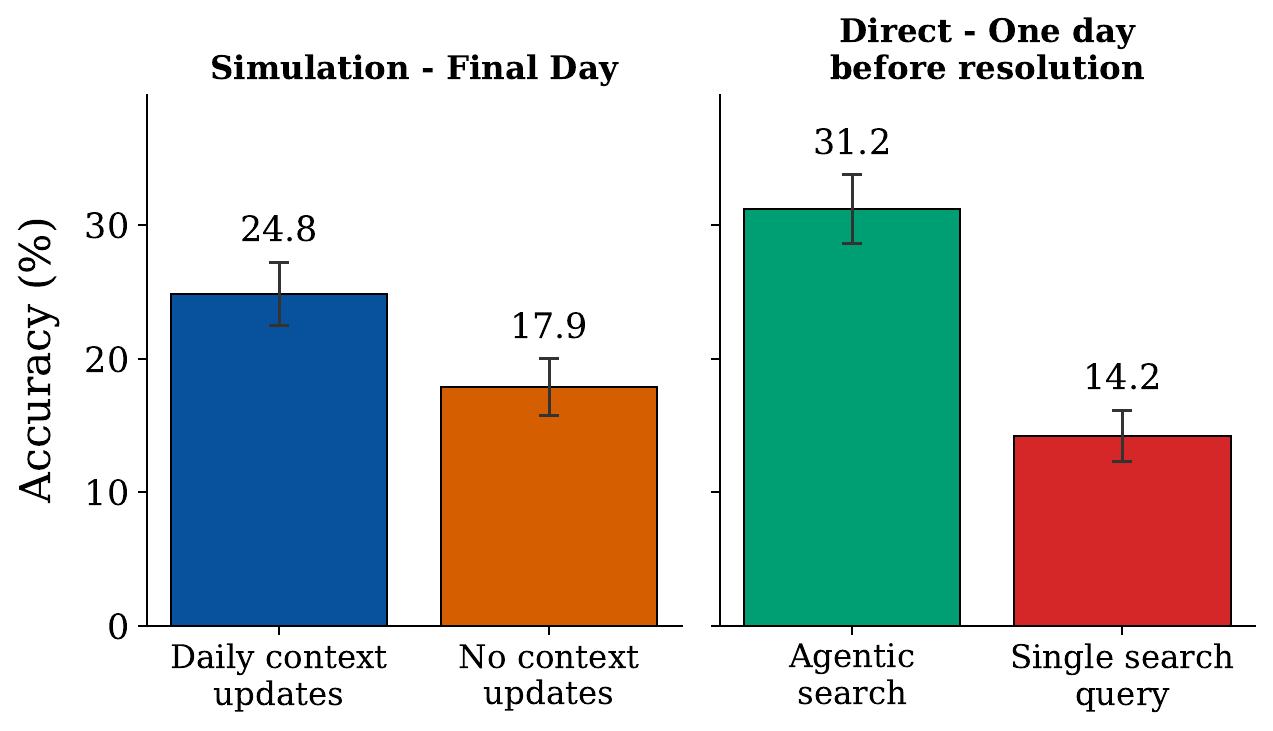
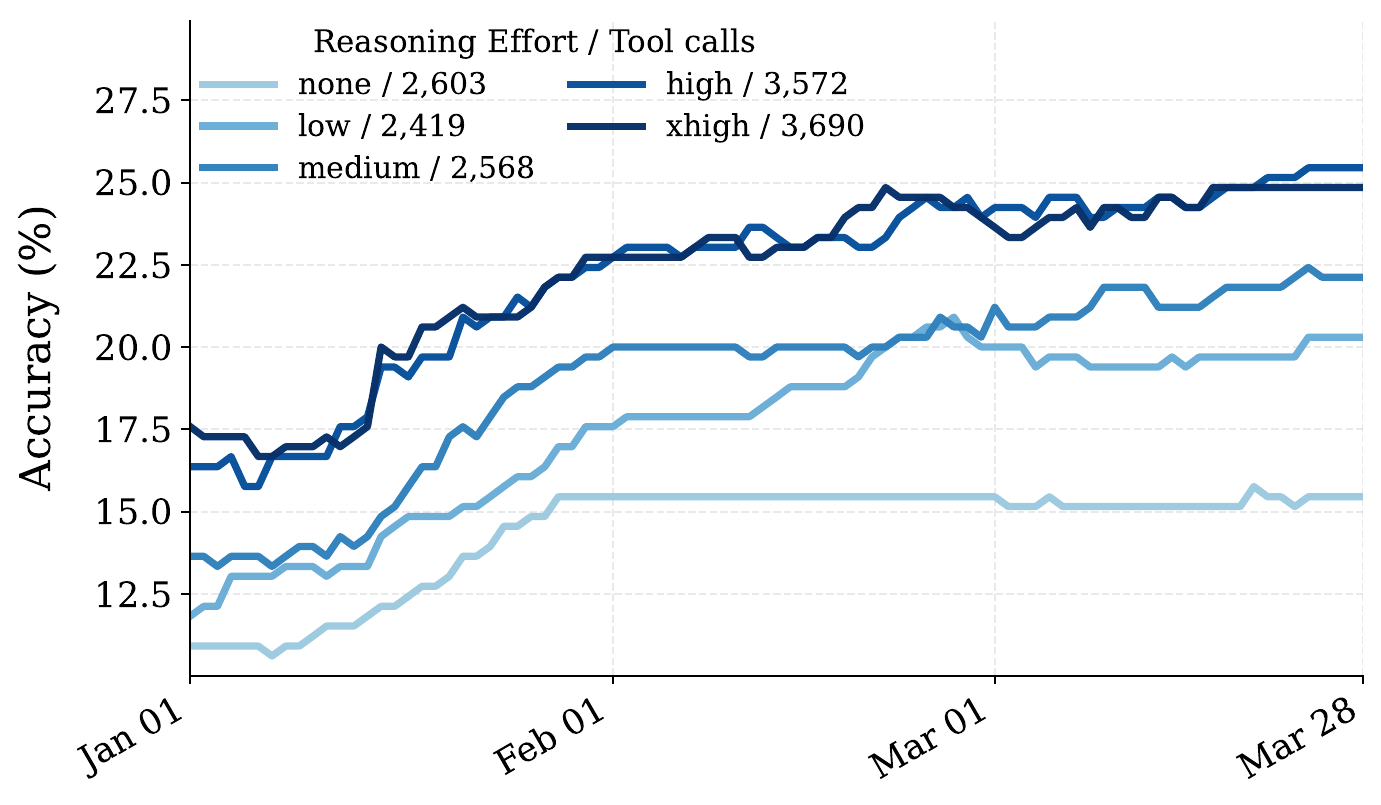
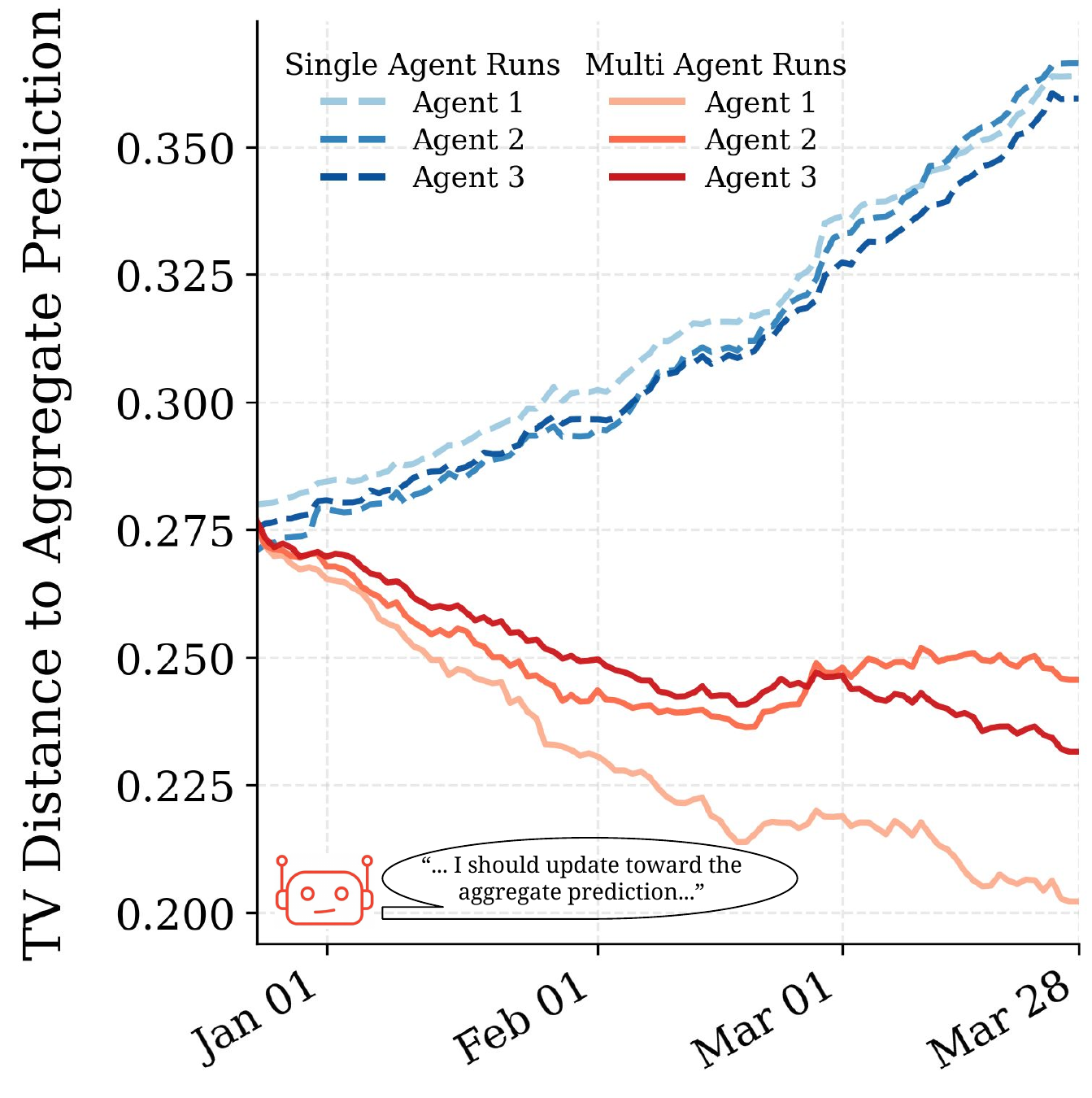
This was just a teaser ;) There are many interesting details and analysis in our paper. Check them out, and let us know what you think!